AI hoạt động như thế nào? Giải thích đơn giản cho người không chuyên
AI (trí tuệ nhân tạo) nghe có vẻ “cao siêu”, nhưng nếu nhìn theo cách đời thường thì phần lớn AI hiện đại chỉ là: một hệ thống máy móc, máy tính, học từ rất nhiều ví dụ để dự đoán, đưa ra câu trả lời. Bài viết này mình sẽ giải thích chi tiết: AI học từ dữ liệu ra sao, mô hình AI là gì, AI “tìm dữ liệu” kiểu nào, và AI tạo câu trả lời như thế nào, theo cách dễ hiểu cho người không chuyên.
AI không “biết tuốt” như con người
Nhiều người vẫn lầm tưởng rằng, AI có bộ não giống như con người và có thể trả lời được tất cả các câu hỏi. Thực tế, hầu hết các mô hình ngôn ngữ lớn (LLM) được xây dựng theo hướng mô hình thống kê mạnh mẽ: nó học các mẫu (patterns) trong dữ liệu và dùng chúng để dự đoán, đưa ra câu trả lời. Các mô hình AI hiện nay được mô tả là mô hình ngôn ngữ tự hồi quy (autoregressive language model), tức là tạo văn bản bằng cách dự đoán dần từng phần nối tiếp nhau.
Điều này dẫn tới 2 hệ quả quan trọng:
- AI có thể trả lời rất trôi chảy vì nó học được cách ngôn ngữ thường vận hành.
- AI có thể sai nếu câu hỏi yêu cầu thông tin ngoài dữ liệu nó học được, hoặc cần kiểm chứng thực tế.
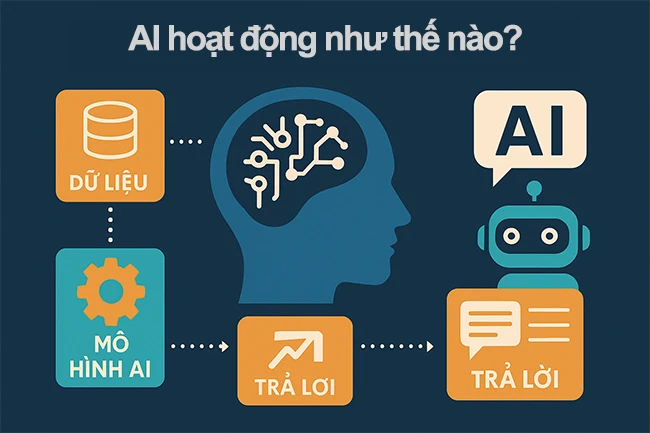
AI hoạt động như thế nào? AI hoạt động dự trên dữ liệu có sẵn và dữ liệu tìm kiếm.
“Mô hình AI” là gì?
Bạn có thể hình dung một hệ thống AI có 3 phần chính:
- Dữ liệu (data): ví dụ: hàng tỷ câu chữ trên web, sách, mã nguồn, tài liệu…
- Mô hình (model): một “cỗ máy” với rất nhiều tham số (parameters), học cách liên hệ giữa các mẫu trong dữ liệu.
- Quy trình huấn luyện (training): cách “dạy” mô hình bằng cách cho nó xem dữ liệu và điều chỉnh tham số để dự đoán ngày càng đúng.
Với AI ngôn ngữ hiện đại, nền tảng kỹ thuật phổ biến nhất là Transformer, một kiến trúc dùng cơ chế attention để xử lý ngôn ngữ hiệu quả, song song và nắm bắt ngữ cảnh tốt.
AI học từ dữ liệu như thế nào?
1. Dữ liệu được “gom” từ đâu?
Dữ liệu mà AI học có thể đến từ nhiều nguồn như: web công khai, sách, bài báo, dữ liệu được cấp phép, mã nguồn, tài liệu do con người tạo,… Trong nghiên về Chat GPT-3, nhóm tác giả mô tả việc huấn luyện mô hình ngôn ngữ rất lớn trên nhiều tập dữ liệu và nhấn mạnh hiệu quả của việc mở rộng quy mô (scale) mô hình và dữ liệu.
Khi trả lời một câu hỏi AI thường lấy dữ liệu có sẵn và có thể tham khảo từ nhiều nguồn hoặc tra cứu trên Google. Dữ liệu huấn luyện thường được dùng để tạo ra “kiến thức nằm trong tham số” của mô hình.
2. Làm sạch dữ liệu và giảm “rác”
Trước khi huấn luyện, dữ liệu thường được:
- Lọc trùng lặp (dedup)
- Loại nội dung kém chất lượng/spam
- Cân bằng nhiều lĩnh vực
- Giảm nội dung độc hại.
Mục tiêu là giúp mô hình học mẫu ngôn ngữ tốt hơn và giảm rủi ro.
3. Huấn luyện: “đoán” rồi sửa sai liên tục
Cách dễ hiểu nhất:
- Mô hình được đưa một đoạn văn và yêu cầu đoán phần tiếp theo.
- Nếu đoán sai, thuật toán sẽ điều chỉnh tham số để lần sau đoán đúng hơn.
- Lặp lại hàng triệu/billions lần trên lượng dữ liệu rất lớn.
Đây là lý do AI “giỏi viết” dù không được dạy từng quy tắc ngữ pháp một cách thủ công: nó học từ ví dụ.
Vì sao Transformer quan trọng?
Trước Transformer, các mô hình xử lý ngôn ngữ thường khó mở rộng do xử lý tuần tự. Transformer dùng attention để “nhìn” nhiều phần của câu cùng lúc, giúp mô hình hiểu ngữ cảnh tốt hơn và huấn luyện hiệu quả hơn. Bài “Attention Is All You Need” đã đề xuất Transformer “dựa hoàn toàn trên attention” và loại bỏ cơ chế hồi quy tuần tự kiểu cũ.
Bạn có thể tưởng tượng attention như đèn pin thông minh: khi tạo một từ, mô hình “rọi” vào những từ trước đó quan trọng nhất để quyết định từ tiếp theo nên là gì.
AI trả lời câu hỏi của bạn như thế nào?

Khi bạn gõ một câu hỏi, AI sẽ thực hiện tuần tự các bước như sau:
Bước 1: Biến câu chữ thành “token”
Máy không hiểu chữ như con người. Nó thường chia câu thành các mảnh nhỏ (token) có thể là từ, một phần của từ, hoặc ký tự. Sau đó mỗi token được biến thành dạng số.
Bước 2: Đưa token vào mô hình để tính xác suất “token tiếp theo”
Với các mô hình AI hiện nay cơ chế cốt lõi là: tính phân phối xác suất của token kế tiếp dựa trên toàn bộ ngữ cảnh đã có (câu hỏi + phần trả lời đã sinh ra).
Bước 3: Chọn token để “ghép thành câu”
Mô hình có thể chọn token theo nhiều chiến lược:
- Chọn token xác suất cao nhất,
- Lấy mẫu (sampling) có kiểm soát để câu trả lời tự nhiên hơn.
Bước 4: Lặp lại cho tới khi hoàn thành
Token nối token tạo thành câu, đoạn, rồi thành cả câu trả lời.
Vì vậy, chatbot “nói chuyện” được không phải vì nó có ý thức, mà vì nó rất giỏi dự đoán chuỗi ngôn ngữ hợp lý dựa trên dữ liệu đã học.
AI “tìm dữ liệu” kiểu gì?
Có 2 kiểu dữ liệu mà AI tìm kiếm:
1. Dữ liệu nằm trong mô hình (parametric knowledge)
Đây là những gì mô hình “học” trong quá trình huấn luyện và được “nén” vào tham số. Khi bạn hỏi, nó không cần truy cập internet vẫn trả lời được các kiến thức phổ thông.
Nhược điểm: thông tin có thể cũ, hoặc mô hình có thể “nhớ sai/ghép sai” → dẫn đến trả lời sai.

2. Dữ liệu lấy từ bên ngoài (retrieval / tool use)
Nhiều hệ thống hiện đại kết hợp mô hình tạo sinh với cơ chế truy xuất tài liệu, hay còn gọi phổ biến là RAG (Retrieval-Augmented Generation).
Trong RAG, hệ thống sẽ:
- Truy xuất (retrieve) các đoạn tài liệu liên quan từ “kho tri thức” (ví dụ: Wikipedia, tài liệu nội bộ, website doanh nghiệp,…)
- Đưa các đoạn đó vào prompt.
- Đưa ra câu trả lời có bám theo nguồn.
Bài nghiên cứu về RAG mô tả mô hình kết hợp “bộ nhớ tham số” (mô hình seq2seq đã huấn luyện) với “bộ nhớ không tham số”, (một chỉ mục vector dày đặc của Wikipedia, truy xuất bằng một retriever).
Điểm hay của RAG:
- Trả lời đúng tài liệu hơn
- Có thể trích nguồn
- Cập nhật kiến thức nhanh bằng cách cập nhật kho tài liệu (không phải huấn luyện lại toàn mô hình).
AI “hiểu” hay chỉ “bắt chước”?
Nhiều người cảm giác AI “hiểu như con người” vì nó trả lời trôi chảy, có vẻ hợp lý, thậm chí biết giải thích lại. Nhưng nếu nhìn theo cơ chế hoạt động, phần lớn AI tạo sinh hiện nay không “hiểu” theo nghĩa có trải nghiệm thực tế, ý thức, hay niềm tin về thế giới. Nó giống một hệ thống học mẫu ngôn ngữ cực giỏi, gặp một ngữ cảnh thì dự đoán “phần tiếp theo” sao cho hợp lý nhất.
Nói đơn giản: AI có thể mô phỏng cách con người nói/viết và suy luận “trên giấy”, nhưng không thể cảm nhận, quan sát, hay sống trong thế giới như chúng ta.
AI không có ý thức, không có cảm xúc
AI có thể nói “mình buồn”, “mình lo”, “mình đồng cảm”… nhưng đó là cách diễn đạt được học từ dữ liệu, không phải cảm xúc thật.
-
Không có trải nghiệm chủ quan: AI không “cảm thấy” đau, vui, sợ, hạnh phúc.
-
Không có mục tiêu tự thân: AI không tự muốn điều gì nếu bạn không yêu cầu; nó phản hồi theo đầu vào và quy tắc hệ thống.
-
Không có ký ức đời sống liên tục như người: Nó không sống qua thời gian để tích lũy trải nghiệm kiểu “hôm qua tôi gặp chuyện này nên hôm nay tôi hiểu hơn”.
Vì vậy, khi đọc câu trả lời của AI, bạn nên coi nó là một công cụ tạo nội dung và suy luận dựa trên mẫu, thay vì một “người” có cảm xúc thật.
AI giỏi “mẫu” nhưng yếu “logic đời thực”
AI đặc biệt giỏi ở những việc “có mẫu” rõ ràng:
-
Viết đoạn văn mạch lạc
-
Tóm tắt nội dung
-
Gợi ý tiêu đề, dàn ý
-
Giải thích khái niệm theo nhiều cấp độ
-
Tạo ví dụ, so sánh, ẩn dụ
Nhưng AI có thể yếu ở “logic đời thực” vì nó thiếu trải nghiệm thực tế. Nó không trực tiếp quan sát thế giới như con người (trừ khi hệ thống được thiết kế có công cụ/nguồn dữ liệu để tra cứu). Một vài tình huống dễ sai:
-
Thông tin cần cập nhật theo thời gian: giá cả, luật mới, tin tức mới, phiên bản phần mềm,…
-
Bài toán cần kiểm chứng chính xác: số liệu, trích dẫn nguồn, tên riêng, lịch sử chi tiết.
-
Suy luận phụ thuộc “bối cảnh ngầm”: thói quen địa phương, quy định nội bộ công ty, dữ liệu riêng của bạn.
-
Chuỗi suy luận dài: đôi khi AI “lạc nhịp” ở bước giữa nhưng vẫn viết ra kết luận rất tự tin.
Bạn có thể hình dung: AI giống một người “đọc rất nhiều” và nói rất hay, nhưng không nhất thiết đã “đi thực tế” để xác nhận.
Ảo giác AI (hallucination) là gì?
Ảo giác AI là hiện tượng AI tự bịa ra thông tin (sự kiện, số liệu, trích dẫn, tên người, đường link, chức danh,…) nghe có vẻ hợp lý, nhưng không đúng hoặc không có thật.
Ví dụ thường gặp:
-
Bịa “nguồn nghiên cứu” kèm tên tác giả/năm xuất bản nghe rất thật
-
Khẳng định một tính năng phần mềm “có tồn tại” nhưng thực tế chưa có
-
Nói sai về số liệu/định nghĩa nhưng diễn đạt rất mượt
-
Kể lại một sự kiện theo kiểu “như đã xảy ra” dù không có bằng chứng
Vì sao xảy ra?
-
Mục tiêu cốt lõi của mô hình là tạo câu hợp lý, chứ không phải luôn luôn “kiểm chứng sự thật”.
-
Khi thiếu dữ liệu chắc chắn, mô hình có thể lấp chỗ trống bằng thứ nghe hợp lý nhất theo ngữ cảnh.
-
Nếu hệ thống không được nối với cơ chế tra cứu tài liệu (RAG) hoặc bạn không cung cấp nguồn, AI càng dễ “đoán mò”.
Cách hạn chế ảo giác khi dùng AI:
-
Yêu cầu AI nêu nguồn hoặc “nếu không chắc thì nói không chắc”.
-
Cung cấp dữ liệu đầu vào (đoạn trích, link, tài liệu) để AI bám theo thay vì tự đoán.
-
Bắt AI tách phần “dữ kiện” và phần “suy luận/đề xuất”.
-
Với nội dung quan trọng, đối chiếu lại bằng nguồn tin cậy hoặc tài liệu gốc.
Vì sao AI đôi khi trả lời “rất tự tin nhưng lại sai”?
Đó là hiện tượng nhiều người gọi là “ảo giác” (hallucination). Một nguyên nhân cốt lõi: mô hình được tối ưu để tạo ra câu trả lời có vẻ hợp lý về mặt ngôn ngữ, chứ không phải lúc nào cũng tối ưu để “đúng sự thật”.
Để giảm chuyện này, các nhóm nghiên cứu thường dùng thêm các bước fine-tune để mô hình:
- Hữu ích hơn
- An toàn hơn
- Bám sát ý định người dùng hơn
Quy trình huấn luyện hiện đại thường có mấy “tầng”?
Một mô hình chatbot mạnh thường trải qua các bước như sau:
- Pre-training: học ngôn ngữ tổng quát từ dữ liệu rất lớn (đoán token tiếp theo).
- Supervised fine-tuning (SFT): học trả lời theo hướng “hỏi đáp”, “làm theo hướng dẫn”.
- RLHF (hoặc biến thể): dùng đánh giá của con người để tối ưu câu trả lời “hữu ích và an toàn” hơn.
Không phải sản phẩm nào cũng công bố chi tiết, nhưng khung ý tưởng này khá phổ biến trong nghiên cứu và thực hành.
Người không chuyên nên hiểu AI theo cách nào?
1. Luôn phân biệt: “AI đang suy luận” hay “AI đang tra cứu”?
- Nếu hệ thống có RAG/tra cứu tài liệu: hãy yêu cầu trích nguồn, hoặc kiểm tra đoạn tài liệu mà nó dựa vào.
- Nếu không có tra cứu: coi như AI đang “tổng hợp từ những gì đã học”, cần kiểm chứng với nguồn tin cậy trước khi sử dụng.
2. Muốn AI trả lời đúng hơn hãy thêm “ngữ cảnh đúng”
Một mẹo rất thực tế:
- Đưa mục tiêu (bạn cần là gì)
- Đưa dữ liệu bạn có (đoạn văn, link, bảng số liệu)
- Đưa tiêu chí (độ dài, giọng văn, định dạng)
- Yêu cầu kiểm tra lại/ghi rõ giả định.
3. Dùng AI cho việc “hỗ trợ” là mạnh nhất
AI thường rất hiệu quả ở các việc:
- Tóm tắt, sắp xếp ý, viết nháp
- Gợi ý cấu trúc bài, tiêu đề, outline
- Giải thích khái niệm
- Viết code mẫu/đề xuất hướng xử lý
- Tạo checklist
Với những việc cần thông tin đúng tuyệt đối như (y tế, pháp lý, tài chính, con số quan trọng), thì bạn hãy coi AI như “trợ lý soạn thảo”, không phải là “nguồn đáng tin cậy nhất”.
Kết luận
AI hoạt động hiệu quả ngày nay chủ yếu nhờ 3 mảnh ghép:
- Dữ liệu lớn + huấn luyện dự đoán giúp mô hình giỏi ngôn ngữ và nhận ra mẫu.
- Kiến trúc Transformer giúp mô hình hiểu ngữ cảnh tốt và mở rộng quy mô mạnh mẽ.
- Fine-tuning với phản hồi con người (như RLHF) hoặc RAG giúp mô hình hữu ích hơn, an toàn hơn, bám ý định và bám tài liệu tốt hơn.

Đại Bee
Xin chào! Mình là Đại Bee. Với nhiều năm kinh nghiệm trong lĩnh vực lập trình, công nghệ AI và truyền thông số, mình sẽ chia sẻ đến bạn những kiến thức, công cụ và kinh nghiệm thực tiễn, giúp bạn đọc không chỉ hiểu về AI mà còn biết cách ứng dụng hiệu quả vào trong công việc, học tập và cuộc sống hàng ngày.
Bài viết liên quan
-

Lợi ích và hạn chế của AI mà bạn nên biết
16/03/2026 • Đại Bee -

AI có thay thế được con người hay không?
16/03/2026 • Đại Bee -

Cách tăng giảm âm lượng trên TV SamSung
16/03/2026 • Đại Bee -

Công nghệ AI là gì? Khám phá tiềm năng và ứng dụng của AI
12/12/2025 • Đại Bee -
Hướng dẫn tạo Proxy từ AWS, Google Cloud và VPS
21/10/2025 • Đại Bee -

Ai là người phát minh ra Công nghệ AI?
21/10/2025 • Đại Bee -

Cách tắt Gatekeeper và SIP trên MacBook nhanh nhất
21/10/2025 • Đại Bee -

Cách sửa lỗi “Failed to connect to your instance” trên AWS
21/10/2025 • Đại Bee -
Lỗi không mong muốn khi đăng nhập Facebook
18/10/2025 • Đại Bee